在構(gòu)建企業(yè)級私有云平臺時,DC/OS(數(shù)據(jù)中心操作系統(tǒng))憑借其卓越的容器編排和資源管理能力,已成為眾多組織的首選。一個健壯、高效的DC/OS私有云環(huán)境,其成功不僅依賴于靈活的軟件定義層,更離不開對底層物理基礎(chǔ)架構(gòu)及其核心組件——特別是數(shù)據(jù)庫——的精細(xì)化、自動化管理。本文將深入探討DC/OS私有云環(huán)境中,物理基礎(chǔ)架構(gòu)管理引擎與數(shù)據(jù)庫管理的關(guān)鍵集成與實(shí)踐。
一、物理基礎(chǔ)架構(gòu)管理引擎:DC/OS的基石
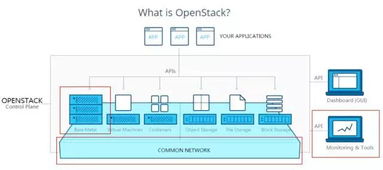
DC/OS私有云的物理基礎(chǔ)架構(gòu)管理引擎,其核心目標(biāo)是將異構(gòu)的服務(wù)器、網(wǎng)絡(luò)和存儲資源抽象為一個統(tǒng)一的、可編程的資源池。這通常通過以下方式實(shí)現(xiàn):
- 資源發(fā)現(xiàn)與注冊:管理引擎自動發(fā)現(xiàn)并注冊新加入的物理服務(wù)器(包括裸金屬或虛機(jī)),收集其CPU、內(nèi)存、存儲和網(wǎng)絡(luò)接口的詳細(xì)信息。對于DC/OS而言,這些節(jié)點(diǎn)被劃分為管理節(jié)點(diǎn)(Master)和代理節(jié)點(diǎn)(Agent),管理引擎需確保它們以正確的角色和配置加入集群。
- 生命周期管理:提供對物理服務(wù)器全生命周期的自動化管理,包括服務(wù)器的上架、操作系統(tǒng)和DC/OS Agent的自動化部署(通常通過PXE、iPXE或預(yù)置鏡像實(shí)現(xiàn))、配置管理、健康監(jiān)控、故障隔離與修復(fù)(如重啟、重裝),以及最終的退役下線。這大幅降低了運(yùn)維復(fù)雜度。
- 硬件抽象與池化:管理引擎將物理硬件細(xì)節(jié)向上層(DC/OS)隱藏。DC/OS Mesos資源管理器從這些節(jié)點(diǎn)上接收統(tǒng)一的資源邀約(Offers),從而可以無視底層硬件差異,調(diào)度容器化或非容器化工作負(fù)載。
- 網(wǎng)絡(luò)與存儲集成:引擎負(fù)責(zé)配置物理網(wǎng)絡(luò)(如VLAN、BGP)和存儲陣列(如SAN、NAS),并通過插件或CNI(容器網(wǎng)絡(luò)接口)、CSI(容器存儲接口)標(biāo)準(zhǔn)向DC/OS暴露網(wǎng)絡(luò)和存儲資源,供應(yīng)用程序動態(tài)申請和使用。
二、數(shù)據(jù)庫管理:DC/OS私有云中的數(shù)據(jù)服務(wù)核心
在DC/OS私有云中,數(shù)據(jù)庫(無論是關(guān)系型的PostgreSQL、MySQL,還是NoSQL的Cassandra、MongoDB,或緩存類的Redis)通常被視為一種重要的“有狀態(tài)服務(wù)”。其管理面臨獨(dú)特挑戰(zhàn):數(shù)據(jù)持久化、高可用、備份恢復(fù)、性能擴(kuò)展。DC/OS通過以下機(jī)制應(yīng)對:
- 框架化部署與管理:許多數(shù)據(jù)庫在DC/OS上以“框架”(Framework)或通過更現(xiàn)代的“服務(wù)”(Service)形式運(yùn)行。例如,Cassandra、HDFS、Kafka都有對應(yīng)的DC/OS服務(wù)包。這些框架是專門為管理特定有狀態(tài)應(yīng)用而設(shè)計的Mesos框架,它們理解數(shù)據(jù)庫的拓?fù)浣Y(jié)構(gòu)、復(fù)制機(jī)制和故障恢復(fù)邏輯,能夠自動化地部署、配置、擴(kuò)縮容和維護(hù)數(shù)據(jù)庫集群。
- 持久化卷支持:DC/OS Mesos支持創(chuàng)建持久化卷,這些卷與任務(wù)(Task)的生命周期解耦。當(dāng)數(shù)據(jù)庫實(shí)例(如一個PostgreSQL pod)被調(diào)度到某個代理節(jié)點(diǎn)時,它可以申請掛載一個預(yù)先創(chuàng)建好的持久化卷,從而確保數(shù)據(jù)在實(shí)例重啟、遷移甚至主機(jī)故障時得以保留。管理引擎需要確保底層存儲(無論是本地SSD還是網(wǎng)絡(luò)存儲)能可靠地提供這些卷。
- 高可用與自動化運(yùn)維:數(shù)據(jù)庫框架通常內(nèi)置高可用機(jī)制。例如,一個數(shù)據(jù)庫框架可以自動部署多個實(shí)例,配置主從復(fù)制,并在主實(shí)例失敗時執(zhí)行故障轉(zhuǎn)移。DC/OS的健康檢查和服務(wù)發(fā)現(xiàn)(通過Marathon-LB或Edge-LB)功能與這些機(jī)制協(xié)同工作,確保客戶端始終連接到可用的數(shù)據(jù)庫端點(diǎn)。
- 統(tǒng)一的服務(wù)發(fā)現(xiàn)與連接:DC/OS提供基于DNS(如Mesos-DNS)或基于負(fù)載均衡器的服務(wù)發(fā)現(xiàn)。應(yīng)用程序可以通過一個穩(wěn)定的服務(wù)名(如
postgresql.marathon.l4lb.thisdcos.directory)訪問數(shù)據(jù)庫,而無需關(guān)心后端實(shí)例的具體IP地址和端口,這簡化了應(yīng)用配置。
三、融合管理:引擎與數(shù)據(jù)庫的協(xié)同
一個先進(jìn)的DC/OS私有云管理方案,會將物理基礎(chǔ)架構(gòu)管理引擎與數(shù)據(jù)庫管理深度集成:
- 智能調(diào)度與放置:管理引擎可以向DC/OS調(diào)度器提供物理硬件的“屬性”(如存儲類型為SSD、GPU型號、特定機(jī)架位置)和“資源預(yù)留”。數(shù)據(jù)庫框架在部署時,可以利用這些屬性進(jìn)行“約束”(Constraints),將數(shù)據(jù)庫實(shí)例精確調(diào)度到具有所需硬件特性的節(jié)點(diǎn)上(例如,將需要高性能IO的數(shù)據(jù)庫實(shí)例調(diào)度到帶有NVMe SSD的節(jié)點(diǎn))。
- 性能與容量監(jiān)控一體化:監(jiān)控系統(tǒng)需要同時覆蓋物理層(服務(wù)器溫度、磁盤SMART狀態(tài)、網(wǎng)絡(luò)帶寬)、DC/OS集群層(Mesos資源使用率)和數(shù)據(jù)庫層(查詢延遲、連接數(shù)、緩存命中率)。統(tǒng)一的監(jiān)控儀表板能幫助運(yùn)維人員快速定位問題根源,例如,判斷數(shù)據(jù)庫性能下降是源于應(yīng)用負(fù)載激增、DC/OS資源競爭,還是底層磁盤故障。
- 災(zāi)備與數(shù)據(jù)流動性:物理基礎(chǔ)架構(gòu)管理引擎可以管理跨數(shù)據(jù)中心或可用區(qū)的資源。結(jié)合數(shù)據(jù)庫自身的復(fù)制工具(如PostgreSQL流復(fù)制、MongoDB副本集)和DC/OS的多區(qū)域部署能力,可以構(gòu)建跨區(qū)域的數(shù)據(jù)庫災(zāi)備方案。引擎還能協(xié)助實(shí)現(xiàn)數(shù)據(jù)的冷熱分層,將不常訪問的歷史數(shù)據(jù)從高性能存儲遷移到成本更低的存儲介質(zhì)。
結(jié)論
在DC/OS私有云中,物理基礎(chǔ)架構(gòu)管理引擎與數(shù)據(jù)庫管理并非孤立的領(lǐng)域。前者為整個云平臺提供了穩(wěn)定、彈性、可編程的硬件底座,后者則在此基礎(chǔ)上構(gòu)建了可靠、高效的數(shù)據(jù)服務(wù)層。通過將兩者緊密集成,組織能夠?qū)崿F(xiàn)從硬件到數(shù)據(jù)的全棧自動化、智能化運(yùn)維,從而充分發(fā)揮DC/OS私有云在敏捷性、資源利用率和運(yùn)維效率方面的巨大潛力,為現(xiàn)代化應(yīng)用提供堅實(shí)支撐。